
Существует много инструментов для анализа кода: они умеют искать ошибки, «узкие места», плохую архитектуру, предлагать оптимизацию. Но много ли среди них инструментов, которые могут не только найти, но и исправить код сами?
Представьте, что у вас есть большой проект на С или С++ (или даже С#), который разрабатывался много лет и многими людьми. В результате разные части проекта выглядят по-разному – нет единого стиля имен переменных, функций, типов данных. То есть в разных частях проекта использовался разный coding style: где-то имена в верхнем регистре, где-то CamelCase, где-то с префиксами, в других местах – без… Некрасиво, в общем.
И вот вы собрались навести порядок, начав, например, с имен переменных. Решили, что все имена должны быть в верхнем регистре и с префиксом по типу данных (так называемая Венгерская нотация).
Вот такое, например, переименование:

Тут некоторые наверняка подумали: «Ну, и в чем проблема? Автозамена же поможет. В крайнем случае скрипт на Python на коленке запилить…»
Хорошо, давайте разберем это: простая автозамена заменит всё и везде, не смотря на области видимости. Если у вас есть переменные с одинаковыми именами и в глобальной области, и в локальных, то все будет переименовано единообразно. Но мы-то можем захотеть давать разные имена, в зависимости от контекста.
Значит, автозамена не подходит. Пишем скрипт на коленке. С областями видимости разобраться не сложно. Но, представляете, переменным, функциям и даже типам данных иногда позволено иметь одинаковые имена. То есть реально, вот такая конструкция вполне себе законна (правда, только в GNU C):
Итак, наш скрипт должен уметь различать контекст, должен понимать, к какой сущности относится символ, должен находить те места, где на него ссылаются. Ничего не напоминает? Мы собираемся написать компилятор! А точнее, ту его часть, которая строит абстрактное синтаксическое дерево.
Абстрактное Синтаксическое Дерево (Abstract Syntax Tree, AST) – это, по сути, ваш исходный код, разобранный на мельчайшие атомы, то есть переменные, константы, функции, типы данных и т.д., которые уложены в направленный граф.
К счастью, строить дерево с нуля нам не нужно – некоторые компиляторы настолько добрые, что готовы поделиться своим деревом с нами. Без регистрации и смс!
Где растут деревья?
Поскольку мы рассматриваем проект на С (или С++), то первым делом вспоминается великий и могучий GNU Compiler Collection, он же GCC.
Front-end в GCC для своих собственных нужд генерирует AST дерево и позволяет экспортировать его для дальнейшего использования. Это, в принципе, удобно для ручного анализа кода «изнутри», но если мы задаемся целью делать автоматические исправления в самом коде, то в данном случае все остальное для этого нам придется написать самим.
Не менее могучий LLVM/clang также умеет экспортировать AST, но этот проект пошел еще дальше и предложил уже готовый инструмент для разбора и анализа дерева – Clang-Tidy. Это инструмент «3-в-1» – он генерирует дерево, анализирует его и выполняет проверки, а также автоматически вносит исправления в код там, где это нужно.
Что также важно для нас – это Open Source проект с доступным исходным кодом, в который легко добавить свои новые функции, если вдруг там чего-то не хватает.
Лес рубят – щепки летят
Для того, чтобы исследовать AST дерево своего проекта, нам понадобится Clang. Если у вас его еще нет, то готовую сборку можно скачать на странице проекта LLVM: https://clang.llvm.org/
Для начала нужно понять, что построение дерева – это часть обычного процесса компиляции. Поэтому нельзя просто взять отдельный файл с исходниками и построить для него дерево. Дерево можно получить только для целой единицы трансляции, то есть набора из файла с исходным кодом и всех требуемых ему зависимостей: подключаемых заголовочных файлов и т.д.
Второй момент: чтобы получить «правильное» дерево, компилировать нужно с той же конфигурацией, что используется в вашем проекте. Если какая-либо единица трансляции в вашем проекте компилируется, например, с ключом -DDEBUG, то и при построении дерева нужно использовать этот же ключ. Иначе ваш код может или вообще не скомпилироваться (тогда вы сразу поймете, что что-то идет не так), или собрать вам неправильное дерево (и вы потратите неделю на то, чтобы понять это).
Первый шаг – убедиться, что ваш проект успешно компилируется в Clang. Если вдруг нет, не стоит отчаиваться. Clang умеет отлично мимикрировать под многие другие инструменты, и, скорее всего, проблему можно решить использованием нужных ключей конфигурации. Правда, документацию все же придется почитать.
Эта команда выдаст все AST дерево сразу:
Вы наверняка удивитесь, насколько оно огромное. Для моего примера “Hello World” выше, из 7 строк кода, дерево получилось в 6259 строк. Это потому, что в нем будет также все, что было подключено из стандартных заголовочных файлов: типы данных, функции и т.д.
Поиск чего-то нужного в таком огромном массиве информации может вызвать уныние, поэтому удобнее использовать команду clang-query для извлечения только нужной информации. Запросы пишутся с использованием специального синтаксиса AST Matchers, который описывается вот тут.
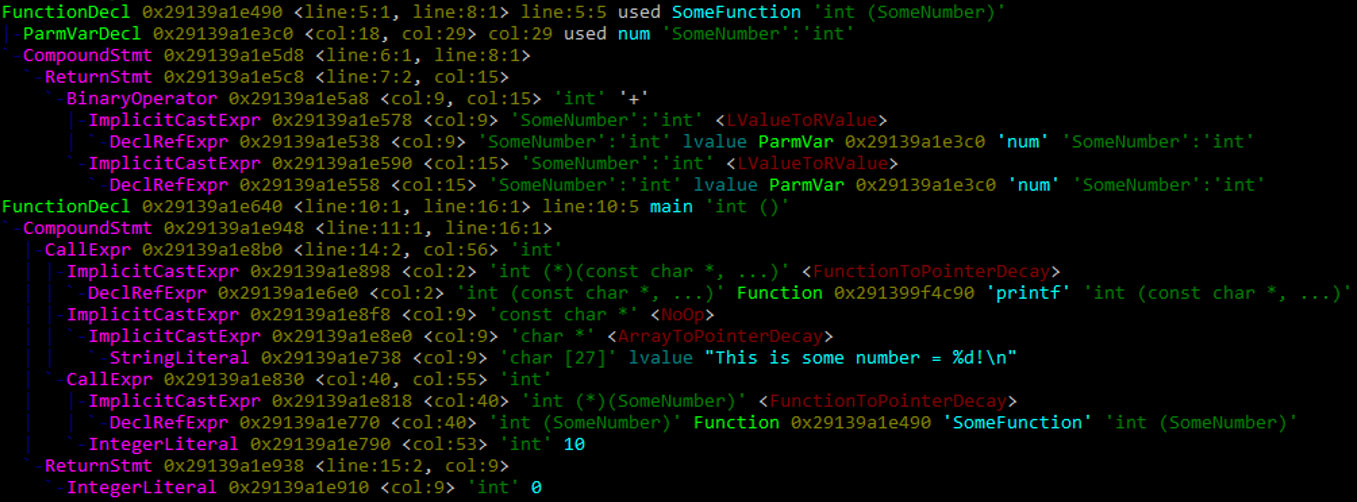
Например, следующий запрос выдаст нам весь внутренний мир функции с именем «SomeFunction»:
Ну, и давайте попробуем запустить сам Clang-Tidy, из спортивного интереса:
Работает! И даже встроенные чекеры подают признаки жизни.
Пристегнитесь крепче – начинаем кодировать!
Про дерево поговорили, пора бы уже переходить к нашей задаче с переименованием.
Первым делом нам нужны исходники LLVM. Да, прямо вот весь проект LLVM, огромный, отсюда: репозиторий.
Еще понадобится cmake, вот здесь.
Удобство проектов, написанных с использованием cmake, заключается в том, что можно автоматически сгенерировать проект для нескольких разных сред разработки. У меня, например, Visual Studio 2019 для Windows, поэтому мой алгоритм получения рабочего проекта выглядит так:
После этих шагов будет сгенерирован LLVM.sln, который можно открывать в Visual Studio и собирать нужные компоненты. Минимальный набор: сам clang-tidy и clang-apply-replacements. Если времени не жалко совсем, то можно построить и весь LLVM, но в целом этого не требуется для нашей задачи.
Интересующие нас исходники находятся в llvm\clang-tools-extra\clang-tidy. Здесь можно посмотреть на примеры других чекеров, то есть модулей в Clang-Tidy для выполнения различных проверок. Они сгруппированы по нескольким категориям, таким как readability, portability, performance и т.д. Их назначение, в принципе, понятно из названия. Здесь же есть скрипт, который поможет нам сгенерировать заготовку для своего чекера:
Здесь «misc» – это категория, в которую мы определили наш чекер, а «ultra-cool-variable-renamer» – это имя нашего чекера.
Скрипт-генератор создаст несколько новых файлов, в том числе для документации и тестов. Но нам на данном шаге интересны только два, в папке misc: UltraCoolVariableRenamer.h и UltraCoolVariableRenamer.cpp
Важный момент: поскольку наш проект для Visual Studio был сгенерирован с помощью cmake, то новые файлы сами по себе в проект не попадут. Для этого нужно перезапустить cmake еще раз, и он обновит проект автоматически.
Собираем и запускаем Clang-Tidy. Видим, что наш чекер появился и показывает сообщения из сгенерированного чекера-заготовки, радуемся этому:
Генератор создал нам не только скелет нового чекера, но и положил в него пример кода, который предлагает немного улучшить имена функций. Эти сообщения мы видим здесь.
Если посмотреть на код самого чекера, то мы увидим что он состоит из всего двух методов: registerMatchers(…) и check(…).
Метод registerMatchers(…)вызывается один раз, при старте Clang-Tidy, и нужен для того, чтобы добавить правила для «отлова» нужных нам мест в AST дереве. При этом здесь применяется такой же синтаксис AST matchers, как мы использовали раньше в clang-query. Затем для каждого срабатывания зарегистрированного правила будет вызван метод check(…).
Сгенерированная заготовка чекера регистрирует только одно правило, для поиска объявлений функций. Для каждого такого объявления будет вызван метод check(), который и содержит всю логику для проверки кода. Нам же, для нашей задачи, нужно проверять переменные, поэтому поменяем этот код на:
Поскольку мы хотим переименовать переменные не только в месте их объявления, но и везде, где они используются, нам нужно зарегистрировать два правила. Обратите внимание на то, что для регистрации правила нужно использовать тот тип объекта из AST дерева, который мы хотим обработать. То есть varDecl для объявлений переменных и declRefExpr для ссылок на какой-либо объявленный объект. Поскольку объявленным объектом может быть не только переменная, то здесь мы применяем еще дополнительный критерий to(varDecl()), чтобы отфильтровать только ссылки на переменные.
Нам осталось написать содержимое метода check(…), который будет проверять имя переменной и показывать предупреждение, если оно не соответствует используемому нами стандарту:
Что здесь происходит: метод check(…) может быть вызван как для объявления переменной, так и для ее использования. Обрабатываем оба этих варианта. Дальше функция checkVarName(…) (оставим ее содержимое за кадром) проверяет соответствие имени переменной принятому нами стилю кодирования, и если соответствия нет, то показываем предупреждение.
Убеждаемся, что мы видим это предупреждение для всех трех мест, где встречается переменная в нашем коде:
Больше трюков – добавляем исправление
На самом деле, мы уже почти все сделали. Чтобы Clang-Tidy не только показывал предупреждения, но и сам вносил исправления, нам осталось добавить пару строчек для того, чтобы описать, как именно и что нужно исправить.
Давайте напишем функцию generateVarName(StringRef oldVarName, StringRef varType), которая будет переводить прежнее имя переменной в верхний регистр и, в зависимости от типа данных, добавлять к ней префикс (примитивное содержимое этой функции также оставим за скобками).
Все, что нам осталось, – это добавить в вывод diag правило замены, указав, где нужно заменить и на что:
Теперь, если мы запустим Clang-Tidy еще раз, то увидим не только сообщения о неправильных именах, но и предложенные исправления. А если запустим его с ключом -fix, то эти исправления будут автоматически внесены в исходный код.
Итак, мы сделали автоматическое исправление всех переменных в нашем проекте, написав меньше 100 строчек кода. Да, этот пример примитивный, он не учитывает многих особенностей и на любом более-менее крупном проекте из коробки не заработает и все сломает… Чтобы такое переименование заработало везде и хорошо, придется еще попотеть. И все же это вполне рабочий прототип, поверх которого можно добавлять ту логику, которую вы захотите.
Бочку мёда видим, где же дёготь?
Что ж, метод хорош, но как же без ограничений? Главное ограничение исходит из самой идеи использования синтаксического дерева: в поле зрения попадет и будет обработано только то, что есть в дереве. То, что в дерево не попало, останется без изменений.
Почему вдруг это может быть плохо?
То, что выключено условной компиляцией, в дерево не попадет. Помните про то, что мы строим дерево, используя реальные параметры вашего проекта? Поэтому, если в вашем проекте есть части кода, которые выглядят, например, вот так:
…то у меня плохие новости – в дерево попадет только то, что не будет вырезано предпроцессором на основе констант вашего проекта. А что тогда делать с «неактивным» кодом? Единого рецепта тут нет: можно запускать Tidy несколько раз, используя разный набор констант, или экспортировать список переименованных символов и дальше пытаться с помощью автозамены обновить оставшиеся части кода. В общем, придется проявить сообразительность и фантазию.
То, что не является исходным кодом, тоже не попадет в дерево. То есть комментарии в исходниках останутся нетронутыми. Если у вас в комментариях упоминаются ваши переменные или функции, то придется вам их обновлять вручную. Еще можно попробовать автоматизировать это внешними средствами, используя информацию о переименованиях, которую Clang-Tidy умеет экспортировать.
Не так все просто с макросами. Они обрабатываются предпроцессором еще до того, как запускается сама компиляция. Это означает, что для правильного переименования символов, которые взаимодействуют с макросами, нужно будет предпринимать дополнительные усилия. Также макросы не присутствуют в AST дереве, хотя возможность их обнаружения и переименования имеется – для этого нужно использовать PPCallbacks.
Как глубока кроличья нора?
С простой задачей разобрались, а что насчет сложных? К этому моменту у вас наверняка возникло много вопросов: насколько умным может быть чекер, что вообще можно им сделать и где черпать идеи?
Прежде всего, с помощью Clang-Tidy можно сделать практически любой анализ и любые манипуляции с исходным кодом. В примере выше мы разобрали работу с переменными как самый простой случай. Однако функции, константы, классы, типы данных и все остальное, из чего состоит код, также разбирается на атомы в AST дереве и также доступно в Clang-Tidy.
В качестве отправной точки для изучения того, какие задачи можно решать с помощью Clang-Tidy и как это можно делать, я советую посмотреть на исходный код других чекеров, который находится там же, в папке с исходниками Clang-Tidy. Это отличное дополнение к официальной документации LLVM, которая, честно говоря, не блещет многословием. Особенно интересно подсмотреть, как сделаны чекеры от Google.
Напоследок хочется пожелать никогда не сдаваться, проявлять изобретательность и фантазию, и… конечно удачи!
Источник — блог Ауриги на Хабре.