
В предыдущей части статьи мы рассмотрели общие подходы к тестированию PDF и познакомились с тем, как библиотеки pdfminer и PDFQuery помогают нам получать детальную информацию об объектах. Достаточно ли нам этой информации? Далеко не всегда. В этой статье мы расскажем о решении некоторых интересных технических проблем.
Делаем свой Page Object
В тестировании веб-страниц уже стал стандартным подход, когда используется архитектурный паттерн Page Object. Он позволяет абстрагировать поиск и идентификацию элементов, а иногда и взаимодействие с ними, от кода самих тестов.
В предыдущей части мы видели, что pdfminer дает нам простой набор элементов, отрисованных на странице. Но нам бы очень хотелось работать не с беспорядочным набором, а уметь обращаться к ним с учетом семантики.
Подходить к решению проблемы можно по-разному, например, можно исходить из ожидаемого положения элементов и искать их по расчетным координатам. Нами был выбран другой подход — с формализацией человеческой логики распознавания объектов.
Поясним на примере. Допустим, у нас есть документ, который содержит таблицу и дополнительные поля:
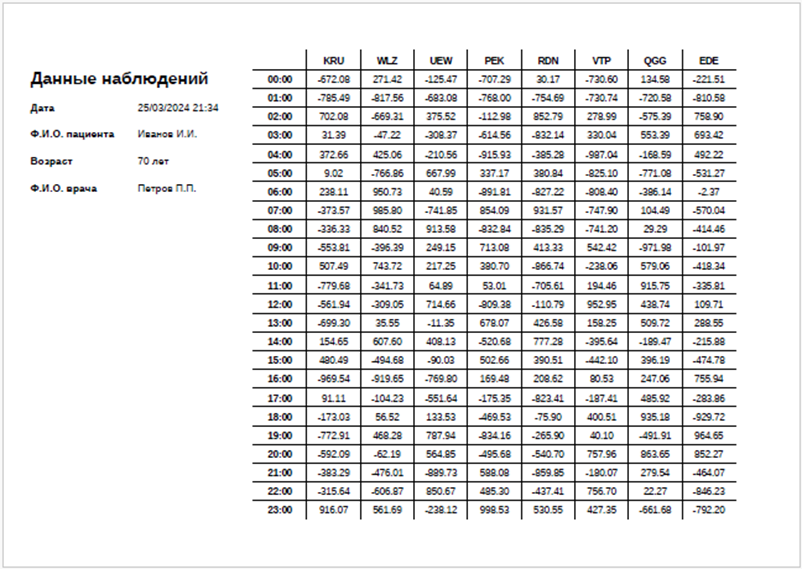
Как бы мы определили, что является табличными данными, а что нет? Кажется, все понятно: табличные данные — это то, что находится внутри ячеек таблицы. Ячейки таблицы — это то, что ограничено линиями или внешними границами таблицы (которые в данном типе документа определяются концами линий). В свою очередь, данные слева от таблицы — это поля с данными, которые включают заголовок и далее пары из меток и значений. Метки и значения — это пары строк, которые не относятся к таблице и расположены на одной высоте.
Теперь давайте решим, как мы хотим обращаться к этим объектам. Например, так:
table_page.table.num_columns
table_page.table.cell[0][4]
table_page.legend.title
table_page.legend.fields[1].labelЧто нужно для этого сделать? Первое — нужно создать иерархию классов, описывающих макет документа, например, так:
from dataclasses import dataclass, field
from typing import Optional
from pdfquery.pdfquery import LayoutElement
@dataclass
class TableLegendField:
label: Optional[LayoutElement]
value: Optional[LayoutElement]
@dataclass
class TableReportLegend:
title: Optional[LayoutElement] = None
fields: list[TableLegendField] = field(default_factory=list)
@dataclass
class TableReportTable:
table_rect: tuple[float, float, float, float] = (0.0, 0.0, 0.0, 0.0)
vertical_lines: list[LayoutElement] = field(default_factory=list)
horizontal_lines: list[LayoutElement] = field(default_factory=list)
# Список ячеек: первый индекс - номер строки, второй - номер столбца
cells: list[list[Optional[LayoutElement]]] = field(default_factory=list)
@property
def num_rows(self) -> int:
return len(self.cells)
@property
def num_cols(self) -> int:
return len(self.cells[0]) if self.cells else 0
@dataclass
class TableReportPage:
legend = TableReportLegend()
table = TableReportTable()
all_elements: list[LayoutElement] = field(default_factory=list)Второе — написать код для заполнения этих объектов элементами со страницы. То есть, надо перенести в код логику, описанную выше, по которой наше собственное сознание относит объекты к тому или иному полю. Например, при инициализации Page Object можно взять первоначальный набор объектов и последовательно применить методы:
self._detect_text_elements()
self._detect_table_lines()
self._detect_table_rectangle()
self._detect_table_cell_contents()
self._detect_legend_elements()Реализацию этой логики в текст статьи вставлять нет смысла: в ней нет ничего шаблонного, и для каждого формата документа распознавание элементов пишется по-своему. Пример рабочего кода можно найти здесь. А здесь — примеры тестов, написанных с помощью нашего Page Object.
На самом деле, правильно разложить объекты бывает совсем непросто, особенно для более сложно устроенных страниц. Но удобство использования оправдывает затраченные усилия.
Получение растровых картинок
Иногда нам нужно получить со страницы изображение, чтобы сравнить его с образцом. Pdfminer отдаст нам элемент класса LTImage, в котором будет поле stream – ссылка на некий объект данных с набором атрибутов:
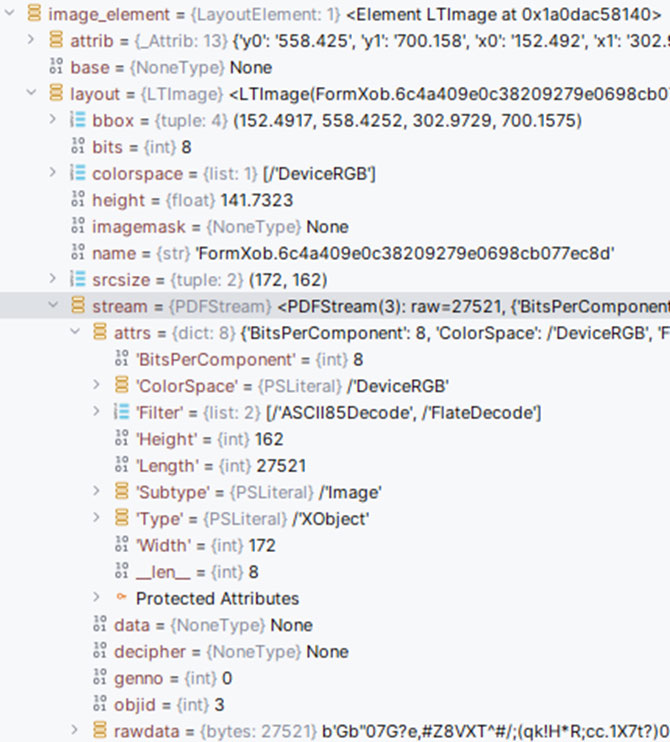
Сама картинка, как можно догадаться, находится в поле stream.rawdata. Преобразовать ее в более удобный формат PIL.Image можно следующим образом:
image_data = image_element.layout.stream
width, height = image_data.attrs["Width"], image_data.attrs["Height"]
image = Image.frombytes("RGB", (width, height), image_data.get_data())Метод Image.frombytes требует выбора режима кодировки цвета. Мы выбираем режим «RGB», который соответствует атрибутам изображения в PDF: ColorSpace = «/DeviceRGB» и BitsPerComponent = 8. Если ваши атрибуты отличаются, возможно, потребуется другой режим.
Пример скрипта с получением изображения можно найти здесь. Чтобы создать файл, с которым он по умолчанию работает, надо запустить этот скрипт.
Ресурсы и метаданные
Иногда мы сталкиваемся с задачами, которые не решаются проверкой свойств элементов. Например, нужно получить доступ к метаданным документа.
Вспомним, что в процессе парсинга PDF мы получаем доступ к двум практически независимым наборам объектов. Один — это набор объектов на странице, который pdfminer формирует после интерпретации потока данных страницы. Второй — это иерархия объектов, которые задают саму структуру файла. О ней мы кратко говорили в первой части статьи, когда описывали устройство формата PDF. К счастью, к этим элементам тоже можно получить доступ.
Порядок работы следующий:
- Получаем экземпляр PDFDocument. При работе непосредственно с pdfminer он создается в явном виде. При работе с PDFQuery он доступен в поле PDFQuery.doc.
- В полях документа уже есть ссылки к некоторым извлеченным парсером объектам, например, PDFDocument.info и PDFDocument.catalog. Некоторые из них, в свою очередь, ссылаются на дочерние объекты. Как только при обходе иерархии мы упираемся в экземпляр типа PDFObjRef, в котором, на первый взгляд, ничего нет, можно вызвать на нём метод resolve(), который вернет полноценный объект.
- Чтобы искать нужные нам пути в иерархии, есть как минимум два способа. Можно поразбираться в спецификации PDF, или же можно, вооружившись REPL питона, исследовать фактическое наполнение документа.
Приведем несколько примеров.
Извлечение растрового изображения
В более старых версиях pdfminer у объекта LTImage не было поля stream, а было только имя объекта в каталоге ресурсов страницы. Получить содержимое картинки по этому имени можно следующим образом:
# Получaем доступ к каталогу страниц
pages_catalog = pq.doc.catalog["Pages"].resolve()
# Получаем доступ к конкретной странице
page = pages_catalog["Kids"][page_index].resolve()
# Получаем доступ к изображению в каталоге ресурсов страницы
image_data = page["Resources"]["XObject"][image_element.name].resolve()
# Далее работаем с картинкой ак же, как в примере вышеПолучение метаданных
Метаданные — это то, что мы видим в диалоге «Document Properties» в Acrobat (автор, дата создания и т.д.). Они хранятся в поле PDFDocument.info.
Полный пример здесь.
Поток данных страницы
Иногда для совместного разбора сложных случаев с разработчиками нужно получить расшифрованный поток данных в виде разархивированного текста. Он доступен по ключу «Contents» в объекте страницы:
pages_catalog = pq.doc.catalog["Pages"].resolve()
page = pages_catalog["Kids"][page_index].resolve()
page_contents = page["Contents"].resolve()Полный пример здесь.
Другие сложные проблемы и изменение библиотек
Напомним еще раз одно важное ограничение pdfminer, о котором говорили в первой части статьи. Это не инструмент для тестирования верстки, это инструмент для извлечения и упорядочивания текстов. И иногда мы сталкиваемся с ситуациями, когда возможностей библиотеки не хватает для тестирования. Но это не такая большая проблема, ведь она написана на Python, и мы можем переделать код для своих нужд.
(Здесь необходимо дать дисклеймер: все изменения в коде библиотеки мы делали в форке во внутреннем репозитории заказчика. В общем доступе их нет, и опубликованы они могут быть только с разрешения заказчика. Нам же далее придется ограничиваться словесным описанием изменений.)
Поговорим про обрезку объектов, текстовые эвристики и повышение производительности.
Все объекты в PDF обрезаются по контуру страницы. То есть в потоке данных ничто не мешает указать координаты для текста или графических элементов, которые выходят за границы страницы, но при рендеринге соответствующие части будут обрезаны (clipped).
Однако можно задать контуры обрезки и внутри страницы. Например, ниже на иллюстрации мы видим один и тот же график, который в одном случае обрезан по границам координатной сетки, а в другом — нет. При этом операторы для отрисовки самой линии графика в обоих случаях будут одинаковые.
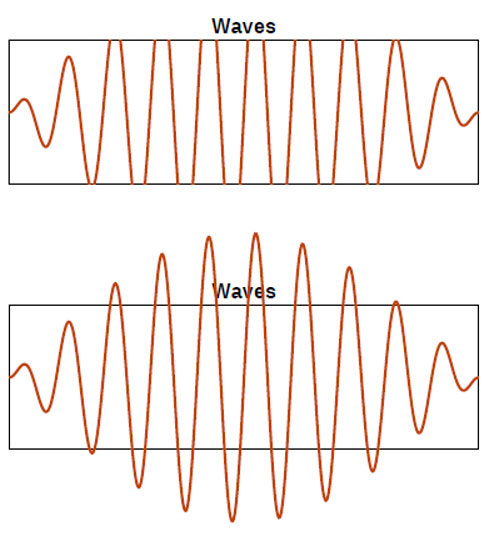
При желании вы можете самостоятельно сгенерировать этот пример с обрезкой и без нее с помощью скрипта, а потом распарсить и сравнить содержимое с помощью этого скрипта. Pdfminer вернет нам график как кривую с набором точек, но мы никак не сможем понять, был он обрезан или был отрисован полностью.
Контур обрезки в содержимом страницы определяется операторами «W» или «W*». Давайте посмотрим, как интерпретатор pdfminer’а обрабатывает эти операторы. Исходный код интерпретатора можно увидеть тут.
def do_W(self) -> None:
"""Set clipping path using nonzero winding number rule"""
return
def do_W_a(self) -> None:
"""Set clipping path using even-odd rule"""
returnИ авторов кода нельзя упрекнуть: контуры обрезки — гораздо более сложная тема, чем кажется на первый взгляд. Обрезка может идти по криволинейному контуру, по самопересекающейся кривой или даже по контуру символов текста. Контуры обрезки могут накладываться друг на друга в разных сочетаниях. Иначе говоря, поддержать обрезку в общем случае — задача сложная и, вероятно, не особо нужная создателям библиотеки.
Решить частную задачу, когда мы имеем дело только с простыми прямоугольными областями обрезки, можно следующим образом:
- Добавляем объектам страницы в pdfminer способность запоминать стек контуров обрезки.
- Добавляем реализацию метода do_W интерпретатора.
- Запоминаем копию стека контуров обрезки в каждом возвращаемом элементе страницы. Да, это увеличивает потребление памяти, но в нашем случае это было некритично.
- Уже на стороне тестового кода мы можем для каждого объекта достать стек контуров обрезки, вычислить их объединение с границами объекта и таким образом получить реальные видимые границы объекта. Нам приходилось работать только с прямоугольными контурами, и вычислять их пересечение было довольно просто.
Ненужные эвристики
С текстом pdfminer работает так:
Шаг первый. В процессе интерпретации потока данных вызывается метод PDFDevice.render_string(). Виртуальное устройство, как уже упоминалось в разделе «Начало работы с pdfminer» в первой части статьи — это та сущность в pdfminer, в контексте которой происходит «отрисовка», а точнее, сохранение всех элементов страницы. Устройств несколько видов, и метод render_string() полиморфен, например, для текстового устройства он будет запоминать только текст без данных о шрифте и других параметрах графики. PDFQuery сразу использует устройство класса PDFPageAggregator, которое собирает максимум данных об объектах. Однако в оригинальной библиотеке pdfminer метод render_string() сохраняет не целые строки текста, а только отдельные символы (LTChar).
Шаг второй. После интерпретации запускается анализ страницы. В процессе анализа pdfminer применяет эвристики, которые и делают его инструментом для извлечения связного текста. Он берет все символы LTChar и с помощью эвристик объединяет их в строки и блоки текста (LTTextLine, LTTextBox).
В большинстве случаев, эвристики работают просто отлично.
Но бывает и так, что они портят нам тесты. Наши документы имеют четкую структуру — по сути, их можно сравнить с формами, где в каждом поле или ячейке таблицы может находиться отдельное значение. Но иногда происходит так, что символы недостаточно далеко отстоят друг от друга — например, когда мы заполняем ячейки таблицы слишком большими значениями:
Pdfminer может решить, что числа расположены достаточно близко, и объединить их в одну строку через пробел. Нам же хотелось бы получать их в виде отдельных строк. В наших документах каждое значение целиком выводится отдельным оператором вывода текста в потоке данных страницы. Иначе говоря, мы не хотим применять эвристики, чтобы узнать, какие символы можно объединить в строки. В самом потоке данных уже есть вся информация о строках.
Для того, чтобы исключить перегруппировку символов, можно предложить такое решение:
- В параметры pdfminer добавляется флаг, позволяющий выключать эвристики.
- Создается перегрузка метода render_string(), которая в случае включения этого флага, формирует объекты LTTextLine сразу в процессе интерпретации страницы и группирует в них нужные символы LTChar.
- Когда pdfminer доходит до фазы анализа, у него уже нет свободных объектов LTChar на странице, и перегруппировка не происходит.
Производительность
Было замечено, что на парсинг документов с таблицами иногда тратится заметное время. На разбор больших многостраничных таблиц могло уходить до нескольких минут.
Для поиска узких мест использовали обычный встроенный cProfile и дополнительно к нему — визуализатор snakeviz.
Оказалось, что больше всего вредит PDFQuery. По умолчанию он пытается выстроить элементы на страницах в иерархическую структуру, определяя по координатам, какие из них находятся внутри друг друга. Сложность алгоритма, очевидно, нелинейная относительно количества элементов на странице, и время обработки сильно растет, когда элементов много, и они мелкие. Эта функция отключается параметром resort=False при создании объекта PDFQuery. Мы в тестах никак не пользуемся результатами пересортировки и самостоятельно формируем page objects, поэтому можем легко выключить этот параметр.
Из других параметров заметный выигрыш дали:
- отключение автоматического округления чисел в PDFQuery,
- отключение эвристик по перегруппировке текста в pdfminer.
После оптимизации параметров основным узким местом остался сам парсинг структуры PDF внутри pdfminer. Пока способов оптимизировать этот код мы не нашли.
В качестве иллюстрации посмотрим на результаты тайминга на примере файла с таблицей, который генерируется нашим скриптом. Сначала не будем передавать библиотеке никаких специальных параметров (оставим все параметры по умолчанию), потом включим все эвристики и обработки по максимуму, а потом отключим то, что можем отключить. Пример скрипта для замера времени находится здесь.
1.019 s - with default parameters
1.044 s - with full analysis
0.159 s - with reduced analysisВот и все. Надеемся, что наш опыт окажется полезным в других проектах.
Источник — блог Ауриги на Хабре.