
Эта статья написана по материалам доклада. Доклад мы делали вдвоем с коллегой. У каждого из нас своя специализация. Здесь я опишу только свою часть.
О проекте
Мы тестировали монитор, который отображает кардиограмму, давление, температуру и другие биомедицинские показатели пациента.
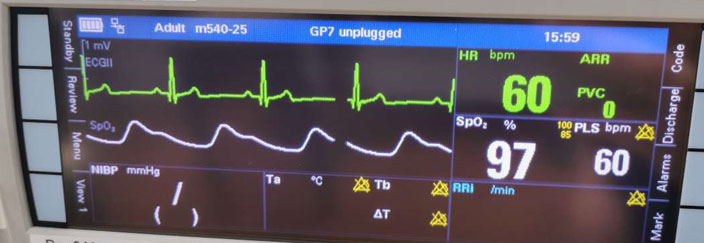
Монитор
Наша компания в данном проекте занимается только тестированием. В том числе, мы разрабатываем инструмент для автоматического тестирования. Этот инструмент является средой, в которой пишутся, отлаживаются и выполняются тестовые сценарии.
Написанием сценариев занимается команда тестировщиков. Эти люди не видят код, зато лучше всех знают требования. Они могут проконсультировать нас по поводу функциональности оборудования, которое мы тестируем. И, что самое важное, они наши внутренние заказчики. Т.е. они прямо говорят нам, какая функциональность нужна им в нашем инструменте.
Тестовый стенд
Прибор тестируется как единое целое, т.е. он анализирует сигналы в процессе теста. Чтобы сформировать сигнал, используется аппаратный симулятор. У него есть интерфейс для автоматизации.

Тестовый стенд
Отчеты о тестах
В разных странах есть требования к процессу разработки медицинского оборудования. В частности, они касаются тестов. Поэтому протокол теста – это документ, который должен быть понятен проверяющим.
В связи с этим формируется документ по той же форме, как для ручного теста: табличка со столбцами Setup, Verify that, Actual result и Verdict.
Формулировки должны очевидным образом соотноситься с требованиями, чтобы показать, что требования покрыты. Verify that и Actual result тоже надо формулировать одинаково.
Как работать с пользовательским интерфейсом
Чтобы автоматизировать тест устройства с сенсорным экраном, требуется:
- Определять, что происходит на экране;
- Симулировать нажатие на определенные элементы интерфейса.
Чтобы нажимать на нужные элементы интерфейса, требуется определять координаты интерактивных элементов.
Мы в процессе тестирования пользовательского интерфейса распознаем его на скриншотах тестируемого устройства.
Говоря о распознавании, часто имеют в виду нейросети и другие алгоритмы машинного обучения. Однако, применительно к нашей задаче, машинное обучение имеет недостатки. Поэтому мы с его помощью решаем лишь некоторые части задачи распознавания GUI. В остальном, мы разбираем изображение по правилам, написанным вручную.
Погрешности
Любое измерение имеет погрешность.
Разность значения, измеренного тестируемым устройством, и значения, выставленного на симуляторе, состоит из следующих слагаемых:
- Погрешность измерения. Она определяется требованиями, на основании которых пишется тест;
- Погрешность симуляции. У симулятора есть класс точности, и он регулярно проходит поверку и калибровку;
- Шумы в кабелях.
Кабель с шумами
Исходя из этих данных определяется диапазон показаний, при которых тест считается пройденным.
Подходы к тестированию UI
Планируя разработку, мы рассматривали следующие подходы к определению состояния интерфейса на экране:
- Чтение исходных данных до рендеринга, т.е. свойств объектов. Для этого нужен какой-нибудь тестовый интерфейс. Если UI-фреймворк открыт и популярен, для него может быть готовое решение, чтобы находить определенные элементы управления, читать их свойства и делать это через сеть. В противном случае придется разработать такой интерфейс;
- Сравнение скриншота с эталоном. В процессе теста сохраняются скриншоты, и при последующих запусках тест требует, чтобы изображение на экране целиком совпадало с сохраненным;
- Распознавание – это комплекс подходов к извлечению информации из изображения.
Рассмотрим каждый подход подробнее и выделим преимущества и недостатки.
Тестовый интерфейс
+ Этот подход позволяет получить цифры, а не пиксели, а значит, мы можем не только сравнивать их с одним ожидаемым значением, но и проверить, попадает ли значение в интервал.
+ Так как рендеринг не тестируется, то его изменение не поломает тест.
— Другой недостаток в том, что для каждого элемента на экране надо проделать некую работу, чтобы элемент был доступен через интерфейс. Эту работу в нашем случае делают разработчики устройства.
Тестовый интерфейс у нас тоже есть. Добавление в него новых элементов требует некоторой работы. Как минимум, надо назначить идентификатор. В некоторых случаях возникают архитектурные сложности. Эту работу делают разработчики устройства.
Каждый раз, как от нас требуется автоматизировать работу с каким-то новым элементом интерфейса, мы создаем для разработчиков задачу. Каждой такой задаче назначают приоритет, добавляют ее в спринт и в конце концов учитывают потраченное время.
Отсюда проблемы межкомандного взаимодействия:
- Во-первых, приходится ждать в лучшем случае начала очередного спринта;
- Во-вторых, при определенном подходе к учету трудозатрат получится, что не мы, а разработчики устройства делают автоматизацию.
Мы видим два выхода:
- Добиваться права самим коммитить в тестовые интерфейсы;
- Постепенно уходить в сторону других подходов, как мы и делаем в этом проекте.
Несмотря на то, что мы уже сделали распознавание, тестовый интерфейс все еще используется по следующим причинам:
- Под него уже написаны тесты, и незачем их чинить, пока они не сломались;
- Кроме изображения с экрана мы тестируем еще звук и устройства ввода: сенсорный экран и кнопки;
- Иногда распознавание сделать сложно, хотя и возможно. По экономическим соображениям в таких случаях выгоднее пройти круги ада с добавлением функциональности в тестовый интерфейс.
Сравнение с эталоном
+ Этот подход тестирует рендеринг, что, несомненно, плюс.
+ Также способ получения скриншотов не приходится менять под каждую задачу.
— Однако, изменение дизайна ломает тест.
— К тому же, если допускается погрешность данных, то нужны эталоны для каждого значения из интервала.
Из требований к продукту не вытекает цвет каждого отдельного пикселя. Поэтому разработчики могут на свое усмотрение подвинуть какой-нибудь элемент на пару пикселей, включить сглаживание при рендеринге шрифта или обновить графический фреймворк.
Пользователь не заметит таких изменений, а тесты упадут. Потребуются затраты на поддержку нового билда продукта тестами. Эти затраты невозможно предсказать. Просто взять и сохранить свежие скриншоты в качестве эталонов было бы безответственно. Необходима ручная проверка, чтобы ошибки не стали эталоном. Я бы не хотел быть тем человеком, которому придется объяснять заказчику, откуда взялись эти расходы.
Распознавание
+ Тестирует рендеринг.
+ Допускает погрешность.
+ Так как используются скриншоты, опять же не надо для каждой задачи менять способ их получения.
+ Распознавание может быть гибким, чтобы допускать изменение дизайна. Но тут необходима оговорка.
На экране видны различные числа, например, значение параметра и его пределы. Если рассматривать только множество строк, то непонятно, какое из чисел что означает. То, что значение выводится большим шрифтом, может показаться очевидным. Тем не менее, это один из аспектов дизайна, который мы фиксируем, и его изменение сломает тесты.
Другой пример. У кнопки есть три состояния: нажата, не нажата и недоступна. Разница между ними только в цвете. Хочешь, не хочешь, а приходится писать условие на цвет.
Остановимся подробнее на том, почему одного только распознавания текста недостаточно для нахождения нужного элемента (предполагая, что на нем есть определенный текст). Для теста важно проверить, что мы нашли, например, кнопку, а не поле с текстом или элемент списка. Если в требованиях сказано, что должна быть кнопка, надо проверить, что это кнопка. В отчете должно быть «Найдена кнопка с таким-то текстом». И отчет должен быть абсолютно честным. Если это окажется невыполнимым, требование останется не автоматизированным.
Динамические элементы
Среди прочего, требуется тестировать динамические элементы:
- мигающий текст;
- чередующиеся сообщения;
- обновляющийся графики.
Через тестовый интерфейс можно просто получить флаг, что текст мигает, и все счастливы.
Если использовать скриншоты, то одного скриншота явно недостаточно. Нужно несколько. Причем, сколько бы скриншотов мы ни сделали, есть риск не увидеть мигание из-за того, что его частота кратна частоте скриншотов.
Резюмируя, получаем следующую картину:
| Тестовый интерфейс | Эталоны | Распознавание | |
|---|---|---|---|
| Тестирует рендеринг | — | + | + |
| Один интерфейс для всех задач | — | + | + |
| Допускает изменение дизайна | + | — | +/- |
| Проверяет мигание, чередование сообщений, обновление графиков | + | — | +/- |
| Допускает погрешность данных | + | — | + |
Распознавание лидирует по всем параметрам.
То, что показание тестируемого устройства случайно, и существует множество допустимых значений – это одна из причин, почему не работает подход с эталонными скриншотами.
Если есть тестовый интерфейс, но нужно обязательно тестировать рендеринг, можно применить комбинированный подход:
- Прочитать измеренное значение через тестовый интерфейс и проверить, попадает ли оно в допустимый интервал;
- Сформировать ожидаемую картинку на основании значения, прочитанного через тестовый интерфейс;
- Сравнить скриншот с ожиданием.
Между измеренным значением и значением на экране не может быть случайного различия – только погрешность округления. Однако, за время между чтением через тестовый интерфейс и снятием скриншота значение может обновиться. Добавить в тестовый интерфейс возможность запрета обновлений – это слишком сильное вмешательство, которое делает тест невалидным.
Кроме того, формировать ожидаемую картинку – значит реализовать такой же рендеринг, как на устройстве, или иметь эталоны для каждого возможного значения параметра.
Так мы приходим к выводу, что скриншоты надо распознавать.
Проблемы машинного обучения в тестировании
Разберем недостатки машинного обучения применительно к задаче тестирования.
Когда понятно, с чем работаешь, машинное обучение излишне
Посмотрев на пользовательский интерфейс, мы можем формально описать, как он выглядит: рамочки и заливка, сплошные и пунктирные линии, что-то внутри чего-то, что-то сбоку.
Таким образом, мы сами формируем модель того, что видим, и не надо ее обучать.
Только заказчик толкует требования
При изменении визуального дизайна у нас нет формальных оснований утверждать, что он сломан.
Если мы сталкиваемся с непонятным кейсом, его надо обсуждать с тестировщиками, а иногда и с заказчиком. Тем более нельзя доверять алгоритмам принимать решения.
Далее будет история про один такой кейс.
Датасет – дорогой продукт
Датасет – сам по себе продукт, причем, дорогой и сложный. Тест же должен быть проще объекта тестирования.
Нужен 100-процентный результат
В машинном обучении модель может ошибаться даже на обучающей выборке. Это логически следует из того, что процесс обучения сжимает выборку произвольного размера до набора параметров модели, количество которых – константа.
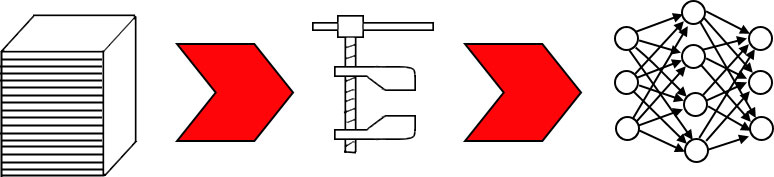
Обучение сжимает данные
Редкие ситуации вообще исключаются из расчетов как статистические выбросы. Такова цена способности модели к обобщению.
Обобщающая способность не очень важна нашему инструменту. Дело в том, что наши тесты не используют элемент случайности. Тесты написаны и закоммичены. Одни и те же скрипты гоняются снова и снова. Ситуация, которую мы неправильно обрабатываем, может обнаружиться в процессе написания тестов. Тогда мы сделаем необходимый фикс. Обобщающая способность может уменьшить наши трудозатраты. Но если нам все же придется обобщать что-то вручную, мы это переживем.
В то же время, ошибки для нас критичны. От нас требуют, чтобы все 100% тестов проходили со 100% вероятностью. Даже самые редкие кейсы надо учесть. Если кейс есть в тестах, то его будут гонять, и пока какие-то тесты не проходят, проект не может быть завершен.
А теперь представьте, что вы используете нейросеть, и у вас налажен процесс исправления ошибок распознавания, который сводится к дополнению датасета и перезапуску обучения. В один прекрасный день этот процесс сломается. Вы обнаружите, что чините один кейс, а другой при этом падает. Такая ситуация неизбежна с ростом датасета. Это будет катастрофа. Придется срочно менять архитектуру сети.
Резюмируем характеристики машинного обучения и вытекающие из них недостатки применительно к тестированию:
| Машинное обучение | Тест |
|---|---|
| Используются только примеры | Объект тестирования понятен |
| Самостоятельно обобщает примеры | Только заказчик трактует требования |
| Требует много данных | Должен быть проще тестируемого продукта |
| Может ошибаться даже на обучающей выборке | Должен стабильно проходить |
Что мы распознаем
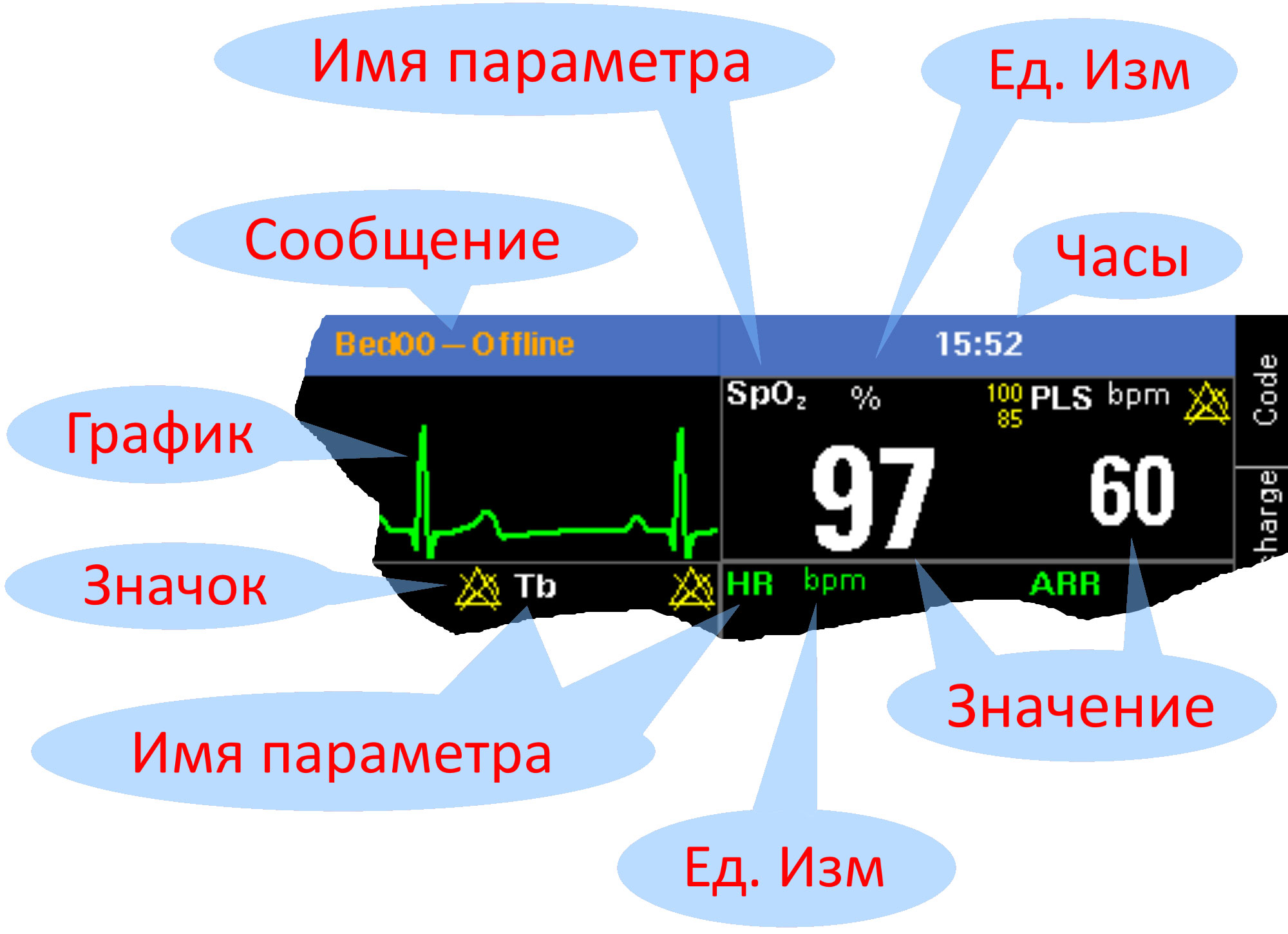
Элементы главного экрана
Структура главного экрана
История о том, как приходится эскалировать найденные проблемы до заказчика.
Главный экран состоит из областей графиков и областей параметров. Распознавание начитается с нахождения этих областей. Затем каждая область разбирается по своим правилам. Каждая область параметров заключена в рамку. Соответственно, я написал алгоритм для нахождения прямоугольников, состоящих из сплошных линий.
Этот алгоритм работал до тех пор, пока граница между графиками и параметрами не стала при определенных условиях пропадать.
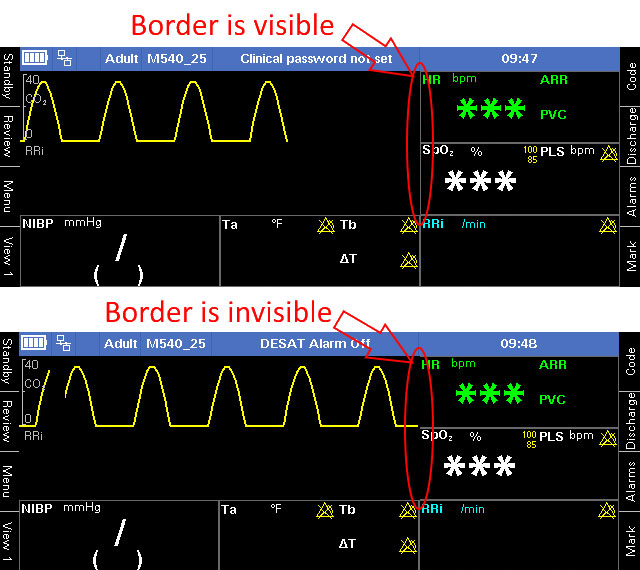
Исчезающая граница
Человек, занимающийся ручным тестированием, сказал бы, что это наша проблема – то, что эти линии нам так важны. Пользователь их даже не видит.
Вместе с тем, отсутствие линий – это баг. Причем, баг в продукте. А мы здесь именно для того, чтобы находить баги в продукте. Так что мы написали о нашей находке заказчику.
Заказчик ответил, что это баг, но низкоприоритетный, и фиксить его не будут. Мы должны работать с тем, что есть. Тесты не должны падать из-за того, о чем не сказано в сценарии.
Получив такой ответ, мы поменяли алгоритм, чтобы находить прямоугольники без одной стороны.
Иконки
Иконка – это изображение, которое не меняется, но может масштабироваться при выводе на экран. Для поиска этих символов не нужны нейронные сети. Однако, из-за искажений при масштабировании искать точное соответствие бесполезно.
Чтобы допускать различную яркость, цвет и интерполяцию при изменении размера, отлично подходят перцептивные хеши. Хеш – это одно 64-битное число. При малом изменении картинки хеш тоже меняется мало.
Перцептивные хеши позволяют хранить только хеш, а не всю эталонную картинку. Благодаря этому данная технология используется для фильтрации запрещенного контента без хранения самого этого контента.
Нам же это свойство не нужно. Мы используем хеши только в качестве метода нечеткого сравнения изображений. Эталонные изображения у нас лежат вместе с исходниками, чтобы было ясно, что с чем сравнивается.
Текст
Напомню, что мы работаем со скриншотами, которые снимаются через программный интерфейс. В них не может быть шума, искажений или заваленного горизонта. Поэтому можно искать попиксельное совпадение с образцом каждого символа.
Однако, для этого нужно собирать эти образцы, и тесты сломаются в случае изменения шрифта. Кроме того, сложность алгоритма будет: ширина * высота скриншота * ширина * высота символа * длина алфавита. Это слишком медленно, если делать в лоб.
С другой стороны, задача распознавания текста давно решена в индустрии. Есть бесплатные библиотеки с предобученными сетями, и они наверняка лучше того, что мы бы разработали сами.
Поэтому мы сделали выбор в пользу нейросетей.
Мы столкнулись с рядом проблем. Чтобы объяснить их суть, сначала расскажу о библиотеке, которую мы используем.
Архитектура PaddleSharp
Так как мы пишем на C#, мы искали библиотеку для C#. Кроме того, разрешение у скриншота меньше, чем у скана или фотографии. Так что нужна была библиотека, оптимизированная для низкого разрешения. Этим требованиям соответствует PaddleSharp.
Библиотека использует конвейер из трех этапов:
- Detector
- Classifier
- Recognizer

Конвейер распознавания текста
Задача распознавания текста состоит из двух подзадач: сначала текст надо найти, а потом уже разобрать на отдельные символы. В PaddleSharp подзадач три. Сейчас объясню.
PaddleSharp умеет находить тексты, повернутые произвольным образом. Нейросеть детектора получает на вход картинку и выдает картинку такого же размера, на которой на месте каждой строки текста сплошное белое пятно.
Далее используются возможности OpenCV, чтобы найти контур каждого пятна и построить вокруг него описанный прямоугольник.
Предполагается, что длинная сторона прямоугольника – это или верх, или низ. А вот точнее определить невозможно. Представление расположения текста с помощью прямоугольника неоднозначно.
Чтобы восполнить этот недостаток информации, используется классификатор. Его задача – отличить перевернутый текст от неперевернутого. На входе картинка, на выходе булевское значение.
Таким образом, задача нахождения текста здесь состоит из двух этапов.
Картинку, содержащую одну строку текста, расположенную привычным для нас образом, можно уже передать в рекогнайзер, и получить результат в виде строки.
График мешает найти текст
Первая проблема связана с детектором. Детектор почему-то не находит текст, если на картинке также присутствует график, даже если график не пересекает текст.

Верхний и нижний графики проходят точно между строками текста. Однако, большинство строк не найдено
Бывает и ложно-положительное детектирование, когда график помечается как текст.
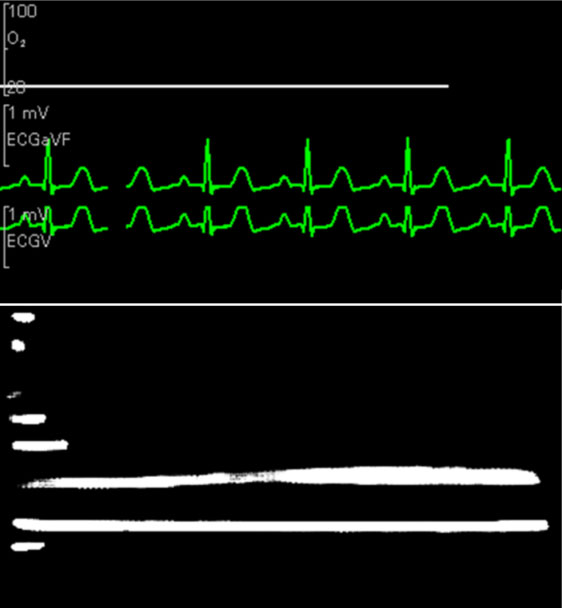
Детектор пометил графики как текст
Одно решение – убрать график с картинки, отфильтровав его по цвету. Цвет текста у нас всегда отличается от цвета графика.

Все тексты найдены
Еще одно решение проблемы с детектором – не использовать детектор. Вместо этого можно объединять близко расположенные фигуры, предполагая, что они образуют одну строку или одно слово.
Такое решение мы тоже используем, только не для графиков, а для параметров.
Распознавание отдельных текстов
Вторая проблема касается рекогнайзера. Некоторые тексты распознаются неправильно.
Предполагаю, что модель для английского языка обучена на текстах из общеупотребительных английских слов. А у нас тут специальные аббревиатуры.
Сообщения из целых слов распознаются лучше.
Так как для каждой картинки результат распознавания всегда одинаковый, работает самое простое решение – словарь для перевода неправильного распознавания в правильное.
Тестовая выборка
Поскольку с распознаванием текста обнаружились проблемы, его надо особенно тщательно тестировать. Для этого нужна тестовая выборка.
Выбирая библиотеку, мы хотели уйти от необходимости собирать датасет, а вышло, что мы все равно его собираем.
Выводы
Выбор в пользу распознавания обусловлен, среди прочего, тем, что наша компания получила контракт только на тестирование. Разработкой тестируемого продукта занимается другая команда.
Если бы команда была одна, эта единая команда могла бы разрабатывать и тестируемый UI, и тестовый интерфейс, принимая во внимание проблемы и того, и другого. Разработка тестов не была бы отдельной статьей расходов, поскольку любая задача на UI подразумевала бы успешные тесты.
Если уж заниматься распознаванием, то стоит всегда рассматривать как подход машинного обучения, так и аналитический подход и делать выбор в соответствии с конкретными условиями.
Источник — блог Ауриги на Хабре.