
Диалоговые системы – одна из классических задач в области обработки естественного языка (NLP). Практически все современные подходы для решения такого класса задач основаны на технологиях глубокого обучения (Deep Learning) с использованием нейронных сетей (Neural Networks) различных архитектур.
Как правило, чат-боты рассматриваются в качестве вспомогательных маркетинговых инструментов для помощи посетителю сайта или социальной сети в выборе товара или услуги. Однако, сфера их применения значительно шире. Эта статья рассказывает о создании корпоративного чат-бота для HR-отдела крупной технологической компании с нуля, т.е. без использования готовых решений. Чат-бот используется для оптимизации рабочей нагрузки сотрудников HR при ответе на часто-задаваемые вопросы. Мы опишем основные шаги для создания работающего прототипа.
Шаг 1. Постановка задачи
Перед нами стояла задача создания чат-бота, целевой аудиторией которого являются сотрудники компании. Система должна уметь отвечать на часто задаваемые вопросы, помогать новичкам в онбординге и поддерживать общение на разные околокорпоративные темы.
В машинном обучении очень важно точно сформулировать бизнес-требования к системе. Обычно это делается в виде написания user-stories. В случае чат-бота наиболее эффективно реализовать их в виде примеров диалогов, желательно разного типа. Например, это могут быть как однофразовые ответы на заданный вопрос , так и диалоги с учётом контекста разной глубины: предыдущая реплика, последние 3-4 предложения, полная история общения с учетом предыдущих сессий с данным пользователем.

Рисунок 1. Пример бесконтекстного диалога из двух пар фраз
Таким образом, собрав набор примеров диалогов разных типов, мы достаточно точно фиксируем требования к разрабатываемой системе.
Шаг 2. Выбор метрик
Второй важный шаг без которого не обойтись, — обсуждение критериев приемки с владельцем продукта со стороны заказчика. В подобных системах разумно использовать два уровня оценки: внешнюю бизнес-метрику и внутреннюю — техническую. В качестве бизнес-метрики целесообразно взять оценку качества работы системы с точки зрения конечного потребителя. В нашем проекте мы подготовили базу из 100 вопросов, и попросили асессоров (несколько десятков сотрудников) оценить качество ответа чат-бота от 0 до 10. Далее оценки асессоров усредняются, и вычисляется значение бизнес-метрики. Недостатком данного подхода является трудоемкость, поэтому для разработки удобно использовать дополнительно внутреннюю техническую метрику, которая вычисляется автоматически. Существует несколько популярных технических метрик для оценивания качества работы NLP — систем, например, perplexity, BLEU, F1, Jaccard score и т.д.
В нашей работе мы использовали Jaccard score. Для вычисления данной метрики необходимо сравнить реальный ответ системы на реплику и идеальный ответ, указанный в датасете. Показатель Jaccard score высчитывается как количество совпадающих слов в этих двух ответах, деленное на сумму: количество совпадающих слов + количество несовпадающих слов из ответа системы + количество несовпадающих слов из идеального ответа . На рисунке 2 метрика Jaccard score подсчитана на примере однофразного ответа системы на вопрос пользователя.
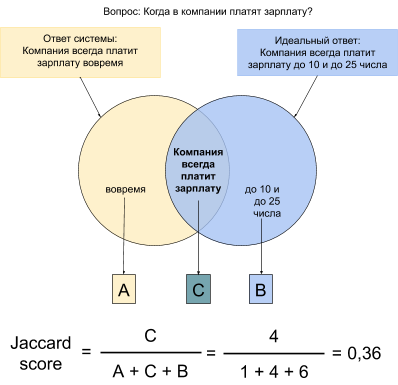
Рисунок 2. Пример вычисления метрики Jaccard score. Сравнивается текст ответа системы на вопрос «Когда в компании платят зарплату?» и идеального ответа
С помощью внутренних метрик можно отслеживать прогресс по задаче и выбирать решения, которые дают наибольший прирост качества. После этого лучшие выбранные решения можно отправить на оценку асессорам для вычисления итоговой бизнес-метрики и планирования дальнейших улучшений с целью достижения удовлетворительных критериев приемки.
Шаг 3. Подготовка выборки для обучения
Следующим шагом является подготовка выборки для обучения системы. В случае чат бота необходим корпус из пар вопрос-ответ. Размер корпуса может составлять от тысячи примеров. Существует прямая зависимость: чем больше размер корпуса для обучения, тем выше качество системы в целом. Например, в одном из известных корпусов — открытом датасете SQuAD — собрано более 100 000 пар вопрос-ответ.
Кроме корпуса общей тематики, обычно необходимо также подготовить специализированный корпус, соответствующий назначению чат-бота. Размер данного дополнительного корпуса определяется имеющимися ресурсами.
В нашем проекте в качестве основного корпуса мы взяли открытый датасет, состоящий из 2 млн пар вопрос-ответ на общие темы. Дополнительно подготовили собственный датасет на основе корпоративной информации, объем которого составил порядка 1000 пар вопрос-ответ на узкую тематику. Эти пары были составлены тремя экспертами независимо друг от друга, что позволило достигнуть большей стабильности полученной метрики, так как для каждого вопроса было предложено 3 эталонных (reference) ответа.
Таким образом, итогом этого шага является два корпуса: большой датасет из пар вопрос-ответ на общие темы и небольшой специализированный датасет по тематике чат бота.
Шаг 4. Выбор архитектуры
Исторически для разработки чат-ботов использовались разнообразные подходы. Существенный прорыв в этой области произошел с началом второй волны применения нейросетей в 2016 году. В то время для NLP-задач обычно использовали рекуррентные нейросети (GRU, LSTM). Однако, начиная с 2018 года акцент сместился в сторону нерекуррентных архитектур с использованием механизма “attention”, в частности на данный момент одним из основных подходов является архитектура “transformers”. На Рисунке 3 показаны state-of-the-art модели за последние два года на примере вышеописанной задачи SQuAD (поиск ответа на вопрос по тексту).
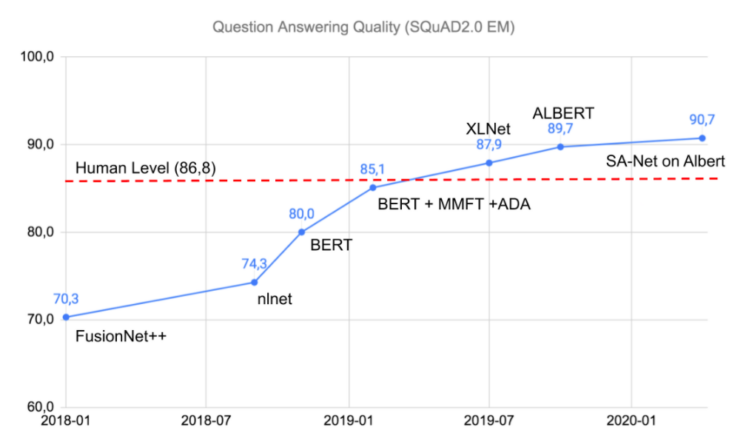
Рисунок 3. Развитие нейросетей различных архитектур на задаче SQuAD, начиная с 2018 года. По вертикальной оси — метрика качества EM (exact match), показывающая примерный процент соответствия ответа нейросети набору эталонных ответов экспертов.
Как видно из диаграммы, в начале 2019 года качество систем стало выше, чем human-level, достигнутый на поставленной задаче асессорами.
Таким образом, в настоящее время рекомендуемым подходом для построения чат-ботов является архитектура “transformers”. В нашем случае были выбраны предобученные модели на основе архитектуры BERT.
Шаг 5. Обучение
После принятия решения об используемой архитектуре начинается обучение выбранной модели. Современные NLP-модели имеют очень высокую сложность и большое количество слоев, поэтому для обучения требуются значительные ресурсы. Например, для того чтобы обучить модель BERT large на корпусе из 800 миллионов слов требуется около 100 GPUdays, что составляет десятки тысяч долларов в денежном эквиваленте (*на момент написания статьи). Поэтому на практике, в качестве основы берут уже предобученные NLP-модели, которые выложены в свободном доступе для многих языков. Однако, такую предобученную модель нельзя напрямую использовать для чат-бота, так как требуется доработка под выбранную задачу, так называемый “fine-tuning” модели. Для этого к предобученной модели добавляются новые выходные слои, и производится дообучение на корпусах из пар вопрос-ответ, речь о которых шла на шаге 3.
В ходе дообучения необходимо контролировать качество с помощью кросс-валидации и автоматических внутренних метрик. После того, как будут достигнуты приемлемые результаты по внутренним метрикам, полученную систему целесообразно отправить на проверку асессорам для вычисления бизнес-метрик и контроля достижения критериев приемки.
В результате получаем обученную модель, которую можно встроить в инфраструктуру чат-бота и начать бета-тестирование итоговой системы на фокус-группах.
В заключение
В данной статье мы постарались описать ключевые этапы построения чат-бот системы: уточнение задачи, определение критериев качества, сбор данных, поиск релевантных моделей и процесс их обучения. Безусловно, приведенный список не является исчерпывающим, и в ходе проекта могут возникать различные нюансы, связанные, например, с поиском предобученных моделей для необходимых языков, настройкой оборудования для обучения моделей, взаимодействия с асессорами и т.д.
Кроме того, для каждого чат-бота характерна собственная специфика, связанная с решаемой задачей и ожидаемой целевой аудиторией. В любом случае, лучшим ориентиром при разработке является обратная связь от конечных пользователей.